Configurazione HA geografica di PostgreSQL¶
Per realizzare una HA geografica di un database PostgreSQL utilizzeremo Stolon: https://github.com/sorintlab/stolon
Architettura di Stolon¶
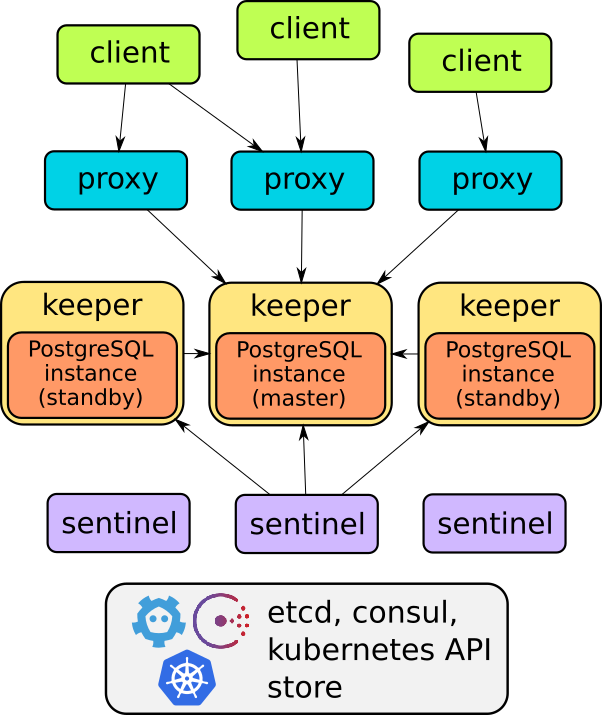
I componenti principali di Stolon sono tre:
- keeper: gestisce una istanza di PostgreSQL che converge sulla ‘clusterview’ calcolata dal sentinel leader.
- sentinel: scopre e monitora i keepers e i proxy e calcola la ‘clusterview’ ottimale.
- proxy: il punto di accesso del client. Forza le connessioni verso il giusto master PostgreSQL e forza la chiusura delle connessioni verso i vecchi master.
Per maggiori dettagli: https://github.com/sorintlab/stolon/blob/master/doc/architecture.md
Stolon ha bisogno di un cluster ETCD per memorizzare informazioni che vengono poi utilizzate dai vari keeper, sentinel e proxy.
Per prima cosa quindi abbiamo bisogno di mettere in piedi un cluster ETCD.
Setup di un cluster ETCD in alta affidabilità¶
Reference: https://github.com/etcd-io/etcd/blob/master/Documentation/demo.md
Scegliamo tre nodi, uno per ogni datacenter, e su ognuno di questi nodi istanziamo un linux container (Ubuntu 18.04).
In questo esempio utilizzeremo i seguenti container: 10.3.0.244, 10.2.0.243, 10.2.244.
NOTA: i container in questo esempio sono disposti solamente su due datacenter, in produzione (come già detto) è consigliabile istanziare i container su tre datacenter diversi per ottenere maggiore resilienza e poter ‘sopravvivere’ alla perdita di uno dei tre datacenter.
Su ognuno di questi container procediamo in questo modo:
Installiamo etcd-server ed etcdctl¶
apt update
apt install etcd
#creiamo una cartella in cui verranno salvati i log di ETCD
mkdir /root/etcd-logs
mkdir /root/etcd-scripts
Configuriamo ETCD sul primo container (10.3.0.244)¶
Nota: rispetto all’esempio riportato nella documentazione di riferimento condivisa più sopra, abbiamo aggiunto i seguenti parametri:
--auto-tls --peer-auto-tls: https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/security.md--quota-backend-bytes=$((6*1024*1024*1024)): aumentiamo a 6GB il limite sulla dimensione del database relativo ad un singolo etcd container--auto-compaction-retention=1: https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/maintenance.md--heartbeat-interval '300' --election-timeout '3000': https://github.com/etcd-io/etcd/blob/master/Documentation/faq.md#what-does-the-etcd-warning-failed-to-send-out-heartbeat-on-time-mean
TOKEN=token-01
CLUSTER_STATE=new
NAME_1=etcd-stolon-test-ct1-srv1
NAME_2=etcd-stolon-test-pa1-srv1
NAME_3=etcd-stolon-test-pa1-srv2
HOST_1=10.3.0.244
HOST_2=10.2.0.243
HOST_3=10.2.0.244
CLUSTER=${NAME_1}=http://${HOST_1}:2380,${NAME_2}=http://${HOST_2}:2380,${NAME_3}=http://${HOST_3}:2380
THIS_NAME=${NAME_1}
THIS_IP=${HOST_1}
#lancia etcd e redirige standard error e standard output nel file /root/etcd-logs/etcd.log
etcd --data-dir=/root/data.etcd --name ${THIS_NAME} --auto-tls --peer-auto-tls --quota-backend-bytes=$((6*1024*1024*1024)) --auto-compaction-retention=1 --heartbeat-interval '300' --election-timeout '3000' --initial-advertise-peer-urls http://${THIS_IP}:2380 --listen-peer-urls http://${THIS_IP}:2380 --advertise-client-urls http://${THIS_IP}:2379 --listen-client-urls http://${THIS_IP}:2379 --initial-cluster ${CLUSTER} --initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN} > /root/etcd-logs/etcd.log 2>&1 &
Configuriamo ETCD sul secondo container (10.2.0.243)¶
TOKEN=token-01
CLUSTER_STATE=new
NAME_1=etcd-stolon-test-ct1-srv1
NAME_2=etcd-stolon-test-pa1-srv1
NAME_3=etcd-stolon-test-pa1-srv2
HOST_1=10.3.0.244
HOST_2=10.2.0.243
HOST_3=10.2.0.244
CLUSTER=${NAME_1}=http://${HOST_1}:2380,${NAME_2}=http://${HOST_2}:2380,${NAME_3}=http://${HOST_3}:2380
THIS_NAME=${NAME_2}
THIS_IP=${HOST_2}
etcd --data-dir=/root/data.etcd --name ${THIS_NAME} --auto-tls --peer-auto-tls --quota-backend-bytes=$((6*1024*1024*1024)) --auto-compaction-retention=1 --heartbeat-interval '300' --election-timeout '3000' --initial-advertise-peer-urls http://${THIS_IP}:2380 --listen-peer-urls http://${THIS_IP}:2380 --advertise-client-urls http://${THIS_IP}:2379 --listen-client-urls http://${THIS_IP}:2379 --initial-cluster ${CLUSTER} --initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN} > /root/etcd-logs/etcd.log 2>&1 &
Configuriamo ETCD sul terzo container (10.2.0.244)¶
TOKEN=token-01
CLUSTER_STATE=new
NAME_1=etcd-stolon-test-ct1-srv1
NAME_2=etcd-stolon-test-pa1-srv1
NAME_3=etcd-stolon-test-pa1-srv2
HOST_1=10.3.0.244
HOST_2=10.2.0.243
HOST_3=10.2.0.244
CLUSTER=${NAME_1}=http://${HOST_1}:2380,${NAME_2}=http://${HOST_2}:2380,${NAME_3}=http://${HOST_3}:2380
THIS_NAME=${NAME_3}
THIS_IP=${HOST_3}
etcd --data-dir=/root/data.etcd --name ${THIS_NAME} --auto-tls --peer-auto-tls --quota-backend-bytes=$((6*1024*1024*1024)) --auto-compaction-retention=1 --heartbeat-interval '300' --election-timeout '3000' --initial-advertise-peer-urls http://${THIS_IP}:2380 --listen-peer-urls http://${THIS_IP}:2380 --advertise-client-urls http://${THIS_IP}:2379 --listen-client-urls http://${THIS_IP}:2379 --initial-cluster ${CLUSTER} --initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN} > /root/etcd-logs/etcd.log 2>&1 &
Verifichiamo lo stato del cluster ETCD¶
Su uno dei tre container diamo i seguenti comandi:
export ETCDCTL_API=3
HOST_1=10.3.0.244
HOST_2=10.2.0.243
HOST_3=10.2.0.244
ENDPOINTS=$HOST_1:2379,$HOST_2:2379,$HOST_3:2379
etcdctl --write-out=table --endpoints=$ENDPOINTS endpoint status
etcdctl --endpoints=$ENDPOINTS endpoint healt
etcdctl --endpoints=$ENDPOINTS member list
Creiamo un servizio per SYSTEMD¶
Configuriamo tutti i container ETCD in modo tale che, al verificarsi di un reboot del container, durante la fase di boot venga automaticamente eseguito uno script che lanci ETCD:
cd /root/etcd-scriptsvi init.sh->#!/bin/sh TOKEN=token-01 CLUSTER_STATE=new NAME_1=etcd-stolon-test-ct1-srv1 NAME_2=etcd-stolon-test-pa1-srv1 NAME_3=etcd-stolon-test-pa1-srv2 HOST_1=10.3.0.244 HOST_2=10.2.0.243 HOST_3=10.2.0.244 CLUSTER=${NAME_1}=http://${HOST_1}:2380,${NAME_2}=http://${HOST_2}:2380,${NAME_3}=http://${HOST_3}:2380 #modificare le variabili 'NAME_X' e 'HOST_X' in base al container THIS_NAME=${NAME_1} THIS_IP=${HOST_1} etcd --data-dir=/root/data.etcd --name ${THIS_NAME} --auto-tls --peer-auto-tls --quota-backend-bytes=$((6*1024*1024*1024)) --auto-compaction-retention=1 --heartbeat-interval '300' --election-timeout '3000' --initial-advertise-peer-urls http://${THIS_IP}:2380 --listen-peer-urls http://${THIS_IP}:2380 --advertise-client-urls http://${THIS_IP}:2379 --listen-client-urls http://${THIS_IP}:2379 --initial-cluster ${CLUSTER} --initial-cluster-state ${CLUSTER_STATE} --initial-cluster-token ${TOKEN} > /root/etcd-logs/etcd.log 2>&1 &chmod +x init.shvi /etc/systemd/system/etcdinit.service->[Unit] Description=etcd startup script [Service] ExecStart=/root/etcd-scripts/init.sh Type=forking [Install] WantedBy=multi-user.target
systemctl daemon-reloadsystemctl enable etcdinit
NOTA: Quando ETCD viene eseguito con il comando etcd –data-dir…, se nel path ‘/root/data.etcd’ il processo trova la directory (creata dopo la prima volta che il comando è stato eseguito ) ignorerà tutti i parametri che iniziano per initial.
Creiamo un cronjob per deframmentare il db dei membri del cluster ETCD¶
All’interno di ciascun container etcd creiamo un cronjob che una volta a settimana deframmenti il db di ciascun etcd. Procediamo come di seguito:
cd /root/etcd-scripts;vi defrag-local-member.sh->#!/bin/sh /usr/bin/etcdctl --endpoints=<ip_container> defrag
chmod +x defrag-local-member.shcrontab - e->#su ogni container etcd, definiamo un #orario che sia ad almeno 5 minuti di distanza dagli altri container #es: 01 01 su primo etcd, 06 01 su secondo etcd, 11 01 su terzo etcd 01 01 \* \* 0 /root/etcd-scripts/defrag-local-member.sh > /root/etcd-logs/defrag.out 2>&1
systemctl restart etcdinit
Setup di un cluster Stolon¶
In questo esempio andremo a replicare il database PostgreSQL del servizio MAAS ma la procedura è valida per qualsiasi servizio che utilizzi un DB PostgreSQL.
Dopo aver configurato con successo un cluster ETCD in HA, andremo a configurare le componenti di Stolon su:
1. la macchina contentente il database da replicare 2. la macchina destinata a contenere la replica.
Le due macchine sui cui installeremo i componenti di Stolon sono container lxc ma potrebbero benissimo anche essere bare metal.
I nodi in questione sono (linux containers ubuntu 18.04) : 10.3.0.232 e 10.2.0.232.
Il nodo 10.3.0.232 è situato nel datacenter di Catania mentre 10.2.0.232 in quello di Palermo.
Su 10.3.0.232 è installato il DB di MAAS. Inoltre, sia su 10.3.0.232 che su 10.2.0.232 sono configurati due MAAS Region Controller. Entrambi i controller utilizzano l’unico database che è installato, come detto in precedenza, su 10.3.0.232
NOTA: si presuppone che MAAS funzioni come ci si aspetti su entrambi i nodi
Nello scenario descritto qui sopra, MAAS ed il suo database sono già operativi ed in funzione. Il nostro scopo è quello di replicare il DB in esecuzione su 10.3.0.232 sul container 10.2.0.232.
Bisogna quindi configurare Stolon a partire da un database esistente. Per fare questo, abbiamo bisogno di inizializzare un cluster di standby come descritto qui: https://github.com/sorintlab/stolon/blob/master/doc/standbycluster.md.
Iniziamo con il preparare entrambi i nodi all’utilizzo di Stolon.
Creiamo un nuovo utente ed installiamo Stolon su 10.3.0.232¶
Creaiamo un utente che verrà utilizzato per eseguire i comandi Stolon:
#passw: 12@st0l0nsu#$ adduser stolonsu
NOTA: è necessario creare un nuovo utente in quanto l’utente root causa problemi al funzionamento di Stolon se è lui ad eseguire i comandi Stolon
Installiamo GO:
add-apt-repository ppa:longsleep/golang-backports apt update apt install golang-go
Compiliamo ed installiamo Stolon:
su stolonsu cd ~ git clone https://github.com/sorintlab/stolon.git cd stolon make
Creiamo delle directories per vari scopi inerenti all utilizzo di Stolon:
cd ~ mkdir stolon-config; mkdir stolon-log; mkdir stolon-data; chmod 0700 stolon-data
Creaiamo un nuovo utente ed installiamo Stolon su 10.2.0.232¶
NOTA: questo è il container su cui non è installato il DB e su cui vogliamo installare la replica
Creaiamo un utente che verrà utilizzato per eseguire i comandi di Stolon:
#passw: 12@st0l0nsu#$ adduser stolonsu
NOTA: è necessario creare un nuovo utente in quanto l’utente root causa problemi al funzionamento di Stolon se è lui ad eseguire i comandi di Stolon
Installiamo GO:
add-apt-repository ppa:longsleep/golang-backports apt update apt install golang-go
Compiliamo ed installiamo Stolon:
su stolonsu cd ~ git clone https://github.com/sorintlab/stolon.git cd stolon make
Creiamo delle directories per vari scopi inerenti all utilizzo di Stolon:
cd ~ mkdir stolon-config; mkdir stolon-log; mkdir stolon-data; chmod 0700 stolon-data
Installiamo postgreSQL 10 se non è installato:
apt update apt install postgresql-10
Prepariamo il DB attualmente in esecuzione ad essere replicato da Stolon (10.3.0.232)¶
Creiamo un Superuser ed un Replication user in Postgresql (Stolon utilizzerà questi utenti per la replica):
su postgres; psql; CREATE USER stolonsu SUPERUSER password '12@st0l0nsu#$'; CREATE ROLE repluser with login replication password '12@r3plus3r#$';
Modifichiamo pg_hba:
add: host replication repluser 0.0.0.0/0 md5
Importante: rimuovere ogni altra replication entry in pg_hba ad eccezione di quella appena inserita
Inizializziamo il cluster Stolon di standby su 10.2.0.232¶
Inizializziamo il cluster Stolon di standby sul container dove non è presente il database di MAAS e creiamo la replica del DB.
Stoppiamo PostgreSQL se in esecuzione:
#quando lanciamo il keeper, Stolon lancerà un processo PostgreSQL. #se Stolon si accorge che esiste già un altro processo PostgreSQL running, keeper fallisce. #da questo, l'esigenza di stoppare PostgreSQL exit; systemctl stop postgresql;
Creiamo un password file da passare a Stolon (a pg_basebackup) per creare il cluster di standby:
su stolonsu; cd ~/stolon-config; vi passfile -> 10.3.0.232:5432:*:repluser:12@r3plus3r#$ chmod 0600 passfile
Creiamo il cluster di standby:
cd /home/stolonsu/stolon #max_connections non va specificato se il DB di MAAS ha il valore di default (100) per questo parametro #specifica il nome da dare allo stolon cluster attraverso il parametro ‘–cluster-name’ bin/stolonctl --cluster-name maas-test-cluster --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 init ' { "role": "standby", "usePgrewind": true, "initMode": "pitr", "pitrConfig": { "dataRestoreCommand": "PGPASSFILE=/home/stolonsu/stolon-config/passfile pg_basebackup -D \"%d\" -h 10.3.0.232 -p 5432 -U repluser" }, "pgParameters": { "max_connections": "300" }, "standbyConfig": { "standbySettings": { "primaryConnInfo": "host=10.3.0.232 port=5432 user=repluser password=12@r3plus3r#$ sslmode=disable" } }, }'
Lanciamo Sentinel:
bin/stolon-sentinel --cluster-name maas-test-cluster --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 > ../stolon-log/sentinel.log 2>&1 &
Lanciamo Keeper e creiamo la replica del DB di MAAS:
bin/stolon-keeper --cluster-name maas-test-cluster --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 --pg-su-username stolonsu --pg-su-password 12@st0l0nsu#$ --pg-repl-username repluser --pg-repl-password 12@r3plus3r#$ --pg-listen-address=10.2.0.232 --pg-port 5432 --uid maas_pa1 --data-dir /home/stolonsu/stolon-data --pg-bin-path /usr/lib/postgresql/10/bin/ > ../stolon-log/keeper.log 2>&1 &
Lanciamo Proxy:
bin/stolon-proxy --cluster-name maas-test-cluster --port 25432 --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 > ../stolon-log/proxy.log 2>&1 &
Verifichiamo lo stato del cluster Stolon appena creato:
bin/stolonctl --cluster-name maas-test-cluster --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 status
Se tutto è andato a buon fine, ora su 10.2.0.232 dove prima non c’era nessun db abbiamo configurato una replica del DB di MAAS in costante sincronizzazione (async replication).
Ci siamo quasi, quello che ci resta da fare ora è:
- Stoppare brevemente i nostri servizi in modo tale che non venga più scritto nulla di nuovo all’interno del database
- Creare una replica su 10.3.0.232 a partire dalla replica presente su 10.2.0.232
- Far puntare entrambi i region controller allo stolon proxy
- Avviare nuovamente i servizi
Stoppiamo i MAAS Region controller¶
Stoppiamo il region controller su 10.2.0.232:
exit; systemctl stop maas-regiond
Stoppiamo il region controller su 10.3.0.232:
exit; systemctl stop maas-regiond
Come risultato di queste operazioni non viene effettuata più nessuna nuova scrittura nel database.
Creiamo una istanza PostgreSQL gestita da Stolon anche su 10.3.0.232¶
Stoppiamo PostgreSQL su 10.3.0.232:
exit; systemctl stop postgresql; su stolonsu; cd ~/stolon
Lanciamo Keeper su 10.3.0.232:
#verrà creata una copia del db presente su 10.2.0.232 e verrà tenuta in sync da Stolon bin/stolon-keeper --cluster-name maas-test-cluster --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 --pg-su-username stolonsu --pg-su-password 12@st0l0nsu#$ --pg-repl-username repluser --pg-repl-password 12@r3plus3r#$ --pg-listen-address=10.3.0.232 --pg-port 5432 --uid maas_ct1 --data-dir /home/stolonsu/stolon-data --pg-bin-path /usr/lib/postgresql/10/bin/ > ../stolon-log/keeper.log 2>&1 &
Lanciamo Sentinel su 10.3.0.232:
bin/stolon-sentinel --cluster-name maas-test-cluster --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 > ../stolon-log/sentinel.log 2>&1 &
Lanciamo Proxy su 10.3.0.232:
bin/stolon-proxy --cluster-name maas-test-cluster --port 25432 --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 > ../stolon-log/proxy.log 2>&1 &
Promuoviamo il cluster Stolon di standby a cluster di ruolo Master (indifferente se da 10.3.0.232 o da 10.2.0.232)
su stolonsu; cd ~/stolon bin/stolonctl --cluster-name maas-test-cluster --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 promote #rimuoviamo i riferimenti allo standby cluster dalla specifica del cluster bin/stolonctl --cluster-name maas-test-cluster --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 update --patch '{ "standbyConfig": null }'
Facciamo puntare entrambi i frontend (maas region controllers) al relativo stolon proxy + restart dei servizi (region controllers)¶
Modifichiamo regiond.conf su 10.3.0.232
exit; #puntiamo al proxy locale di Stolon vi /etc/maas/regiond.confg --> db_host=localhost db_port=25432 systemctl restart maas-regiond
Modifichiamo regiond.conf su 10.2.0.232
exit; #puntiamo al proxy locale di Stolon vi /etc/maas/regiond.confg --> db_host=localhost db_port=25432 systemctl restart maas-regiond
Congrats! Il DB di MAAS è in HA.
Abbiamo quasi terminato, mancano gli ultimi accorgimenti.
Disabilitiamo PostgreSQL su 10.3.0.232¶
Configuriamo entrambi i container in modo tale che in occasione di un reboot, il servizio PostgreSQL non parta in automatico. Questo permette di evitare problemi con Stolon dopo un eventuale reboot del container.
systemctl disable postgresql
Disabilitiamo PostgreSQL su 10.2.0.232¶
Configuriamo entrambi i container in modo tale che in occasione di un reboot, il servizio PostgreSQL non parta in automatico. Questo permette di evitare problemi con Stolon dopo un eventuale reboot del container.
systemctl disable postgresql
Creiamo un servizio per SYSTEMD¶
Configuriamo entrambi i container dei Region di MAAS in modo tale che, al verificarsi di un reboot del container, durante la fase di boot venga automaticamente eseguito uno script che lanci Proxy, Keeper e Sentinel:
su stolonsu; cd ~mkdir stolon-scripts; cd stolon-scriptsvi init.sh->#!/bin/sh /home/stolonsu/stolon/bin/stolon-proxy --cluster-name maas-test-cluster --port 25432 --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 > /home/stolonsu/stolon-log/proxy.log 2>&1 & #modificare con il giusto ip e uid /home/stolonsu/stolon/bin/stolon-keeper --cluster-name maas-test-cluster --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 --pg-su-username stolonsu --pg-su-password 12@st0l0nsu#$ --pg-repl-username repluser --pg-repl-password 12@r3plus3r#$ --pg-listen-address=10.3.0.232 --pg-port 5432 --uid maas_ct1 --data-dir /home/stolonsu/stolon-data --pg-bin-path /usr/lib/postgresql/10/bin/ > /home/stolonsu/stolon-log/keeper.log 2>&1 & /home/stolonsu/stolon/bin/stolon-sentinel --cluster-name maas-test-cluster --store-backend etcdv3 --store-endpoints http://10.3.0.244:2379,http://10.2.0.243:2379,http://10.2.0.244:2379 > /home/stolonsu/stolon-log/sentinel.log 2>&1 &
chmod +x init.shexit; vi /etc/systemd/system/stoloninit.service->[Unit] Description=stolon startup script [Service] User=stolonsu ExecStart=/home/stolonsu/stolon-scripts/init.sh Type=forking [Install] WantedBy=multi-user.target
sudo systemctl daemon-reloadsudo systemctl enable stoloninit
Stolon command line utilities¶
Dopo aver effettuato lo switch dell’utente (su stolonuser), possiamo utilizzare i seguenti comandi:
#Per verificare lo stato del cluster
stolonctl --cluster-name <nome-cluster> --store-backend etcdv3 --store-endpoints <ip1:port1, ip2:port2..> status
#Per verificare l'attuale configurazione del cluster
stolonctl --cluster-name <nome-cluster> --store-backend etcdv3 --store-endpoints <ip1:port1, ip2:port2..> spec
#Per causare il fail di un keeper(ad esempio il master keeper) e provocare l'elezione di un nuovo master
stolonctl --cluster-name <nome-cluster> --store-backend etcdv3 --store-endpoints <ip1:port1, ip2:port2..> failkeeper <keeper_uid>
#Per modificare uno più parametri di configurazione nel DB su tutti i membri del cluster usiamo la parola chiave update --patch seguita da una configurazione
##In questo esempio aggiorniamo il parametro max_connections a 300 su tutti i membri ed effettuiamo il restart di tutti i membri
stolonctl --cluster-name <nome-cluster> --store-backend etcdv3 --store-endpoints <ip1:port1, ip2:port2..> update --patch '{ "pgParameters": { "max_connections": "300" }, "automaticPgRestart": true, "mergePgParameters": false }'
Troubleshooting¶
Stolon Proxy non è raggiungibile da container o macchine diverse da quella su cui gira¶
Se Stolon Proxy viene eseguito su una macchina diversa da quella in cui è installato il servizio che fa uso del DB e se il suddetto servizio non riesce a stabilire una connessione con lo Stolon Proxy, è possibile che Stolon Proxy sia stato lanciato senza il parametro –listen-address.
Stolon Proxy si mette in ascolto implicitamente su localhost ma se eseguito su un container o macchina diversa deve essere lanciato con un ulteriore parametro:
`--listen-address <ip-container/macchina>`
ETCD DB size¶
Di default, il limite della dimensione del DB di ETCD è settato a 2GB (https://github.com/etcd-io/etcd/blob/master/Documentation/dev-guide/limit.md).
Se la dimensione del DB supera il limite dei 2GB (su qualsiasi membro del cluster), il cluster ETCD esegue le seguenti operazioni:
- lancia un allarme
- rifiuta richieste di scrittura, bloccando di fatto Stolon (che dipende da etcd)
Il limite sulla dimensione del DB può essere aumentato a massimo 8GB aggiungendo il parametro –quota-backend-bytes al comando etcd.
È dunque essenziale che la dimensione del DB non superi il limite configurato (bisogna monitorare ciascun membro del cluster)
Per liberare spazio, oltre al compattamento, etcd ha bisogno della deframmentazione.
“Compacting is a background process which doesn’t block the database but it can result in more memory being used as the keys and revisions are reorganized.
That fragmented memory is tidied up when a node is asked to defragment. This reclaims all the memory from the keys and values that were compacted away. Each node on a etcd cluster can be scheduled to run a defrag job once every 24 hours, each node running on a different hour. Thats because defrag, unlike compact, blocks the server.
So at any time, the three nodes in a etcd cluster could be showing different db sizes. Defragged at different times and with different numbers of revisions retained and compacted, its pretty unlikely the numbers would line up.” (https://www.compose.com/articles/how-to-keep-your-etcd-lean-and-mean/)
Reference: https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/maintenance.md
etcdserver: mvcc: database space exceeded¶
Questo è un errore che si verifica nel momento in cui la dimensione del db di uno dei membri del cluster etcd ha superato la soglia configurata. L’errore può essere riportato dal comando stolonctl status e/o può essere visualizzato sui container etcd.
Procediamo come di seguito su uno dei tre etcd server:
cd;
rev=$(ETCDCTL_API=3 etcdctl --endpoints=$ETCD_ENDPOINTS endpoint status --write-out="json" | egrep -o '"revision":[0-9]*' | egrep -o '[0-9].*')
#Se il comando ha bisogno di un solo argomento, diamogli uno dei numeri memorizzati nella variabile 'rev'
ETCDCTL_API=3 etcdctl compact $rev --endpoints=$ETCD_ENDPOINTS
ETCDCTL_API=3 etcdctl defrag --endpoints=$ETCD_ENDPOINTS
ETCDCTL_API=3 etcdctl alarm disarm --endpoints=$ETCD_ENDPOINTS
Reference: https://github.com/etcd-io/etcd/blob/master/Documentation/op-guide/maintenance.md
etcd: failed to send out heartbeat on time (exceeded the 100ms timeout for 11.293654ms); etcd: server is likely overloaded¶
Se nei log letti con il comando journalctl -u etcdinit troviamo questo errore, procediamo come di seguito per ogni etcd:
- modifichiamo /root/etcd-scripts/init.sh aggiungendo i parametri –heartbeat-interval ‘300’ –election-timeout ‘3000’ al comando etcd
systemctl restart etcdinit
Stolon fallisce nell’eseguire un pg_basebackup¶
Se durante l’inizializzazione di uno stolon standby cluster Stolon sembra bloccarsi nell’esecuzione del pg_basebackup, il problema potrebbe essere riconducible al fatto che l’istanza di postgresql di cui vogliamo fare una copia non è abilitata alla replica.
Postgresql 10 di default è configurato ad essere replicato mentre Postgresql 9.6 no.
Abilitiamo dunque postgresql ad essere replicato inserendo i seguenti parametri all’interno del postgresql.conf:
- wal_level = ‘replica’
- max_replication_slots = ‘20’
- max_wal_senders = ‘47’
- wal_log_hints = ‘on’
- wal_keep_segments = ‘8’
